
- 臺灣科技大學資訊工程系 109學年度第二學期 ( 2021/2/24 - 2021/6/23 )
- 課程名稱:人工智慧與邊緣運算實務
- 課程代號:CS5149701
- 課程講師:許哲豪 (Che-Hao,Hsu / Jack Hsu) 博士
- 【課程說明】
摘要說明
透過照片或影片畫面辨識出車牌號碼後,可以用於檢查自定義的違規車牌資料庫內是否有該違規車牌,以達到檢測違規車輛之用途。
系統簡介
創作發想
常常看到路邊的停車格計費員在進行收費,利用手上的計費機辨識出車牌後開收費單,因此想到如果還可以搭配檢查該車牌是否為違規車輛,讓計費員可以通報後進行後續處置。
硬體架構
目前設計可以輸入照片或是影片做為分析,使用 Google Colab 進行自定義車牌偵測模型訓練,並於 Google Colab 上進行照片、影片推論。
原先有要嘗試在樹莓派 (Raspberry Pi) 進行推論,由於後來疫情關係沒找到鏡頭因此沒在樹莓派上嘗試。
工作原理及流程
推論的流程共分為三部分,分別為「車輛偵測」-「車牌偵測」-「車牌 OCR」。
接收到輸入的影像後,會先使用預訓練的 yolo-v4 coco 偵測出畫面上的車輛(汽車、摩托車),再使用自己另外訓練的自定義的車牌偵測資料集偵測出車牌位置後,再使用 tesseract 在車牌位置上進行 OCR 辨識。

資料集建立方式
總共使用論文提供的資料集以及自己另外收集的資料集:
論文資料集
Application Oriented License Plate(AOLP) Database1: http://aolpr.ntust.edu.tw/lab/index.html
該資料集共有三種分類,如下圖由左至右分為:
- Access Control (AC)
- Road Patrol (RP)
- Traffic Law Enforcement (LE)

另外收集的資料集
我有另外自行收集行車記錄器的影片截圖來仿造 AOLP 資料集(如下圖),與 AOLP 資料集比較不同的點是:
- 目前有些車牌為 7 碼,AOLP 的都是 6 碼不知道會不會有影響
- 另外原資料集的部分都是汽車車牌截圖,我自行產生的部分有一半是機車車牌截圖

模型選用與訓練
- 車輛偵測: 直接採用了 yolov4 預訓練的 COCO 資料集模型,用於偵測出畫面上的汽車、機車位置。
- 車牌偵測: 這邊我們使用 yolov4-tiny 自定義上述的資料集,使用 darknet 對資料集進行訓練及推論。
- 車牌 OCR 辨識: 使用 tesseract 作為 OCR 辨識模型,在車牌偵測的模型後得到車牌位置後,將車牌圖片進行OCR辨識得到車牌字元。
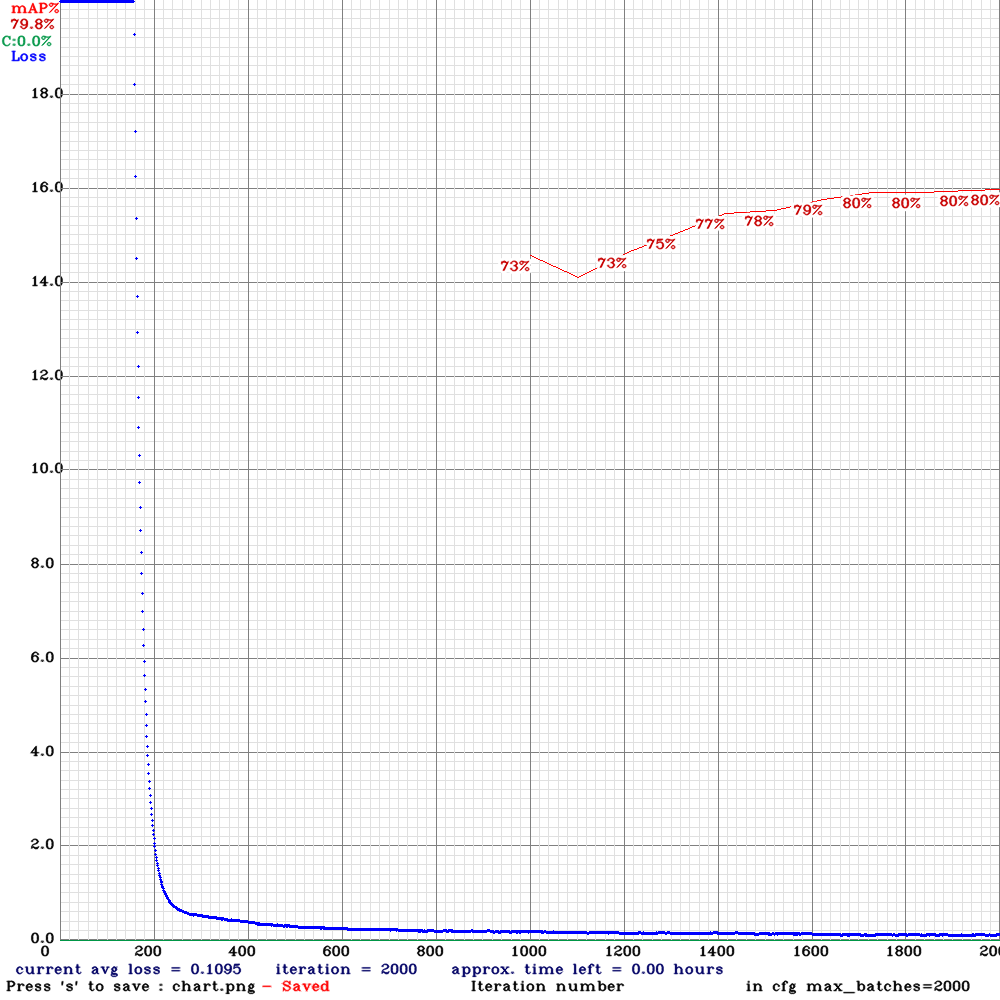
下圖為車牌偵測模型的訓練過程損失(Loss)及類別平均精確度(mAP)變化圖
實驗結果
成果展示說明
由於疫情期間,因此不便外出拍攝街道停車格影片,因此這邊使用從網路上找到的行車記錄器影片來做測試範例:
如下圖我們可以看到我們訓練出的模型可以很正確的框出車牌的位置,另外在我們自定義的違規車牌列表中,也有偵測到違規的車牌號碼,在繪製結果圖時,程式也會將違規車牌號碼顯示在畫面上。

原先一開始打算直接用資料集訓練車牌偵測模型,但是在實際測試的過程中發現由於資料集都是直接輸入只有車子的畫面,並沒有像行車記錄器那樣的廣角視角,因此才會先多用一層 COCO 模型去先找出汽車、機車的位置,但也有因此減慢了在推論過程中的速度。

改進與優化
這邊提出兩個後續改進的方向:
合併 COCO 和 自定義車牌偵測 模型
應該可以先用目前的推論流程在偵測出車牌位置後,另外收集成新的資料集來重新訓練一個新模型,應該就可以減少兩層模型的推論時間。
車牌清晰化
在推論影片的過程中也有發現畫面在移動的過程中,常常會遇到模糊的問題,這邊或許可以參考網路上的做法,訓練出基於 GAN 的模型,將模糊不清的車牌經過模型後變清楚
比較與測試
這邊原先預計使用 OpenVINO 釋出的車牌偵測模型 vehicle-license-plate-detection-barrier-0106 來作為車牌偵測的比較對象,但經過測試後發現該模型貌似並不支援台灣的車牌。

結論
經過測試後可以發現訓練的模型可以正確地找到車牌的位置,但在 OCR 的部分常因為畫面模糊而導致 OCR 辨識不良,後續可以透過修改影像強化或是額外訓練模型來做改善。
參考文獻
- 許哲豪 - 如何以Google Colab及Yolov4-tiny來訓練自定義資料集─以狗臉、貓臉、人臉偵測為例
- Github - AlexeyAB/darknet
- iThome - Day26-聽過 OCR 嗎? 實作看看吧 – pytesseract
附錄
Colab源碼
- 自定義車牌偵測模型訓練程式碼

- 測試推論結果範例程式碼
資料集及標註檔
由於車牌某部分也是屬於個資的部分,這邊提供我自己收集的部分資料集作為訓練範例,且僅作為學術研究使用,不得用於其他用途,已經將訓練集和驗證集的影像和標註檔分別放置在 yolo_train, yolo_valid 資料夾中。

G. Hsu, J. Chen and Y. Chung, “Application-Oriented License Plate Recognition,” in IEEE Transactions on Vehicular Technology, vol. 62, no. 2, pp. 552-561, Feb. 2013, doi: 10.1109/TVT.2012.2226218. ↩︎